
Redis is an in-memory key-value datastore that is mostly used as a highly performant caching solution , A fully fledged database , a message broker or a streaming engine.
It was first released in 2009 and has emerged as a robust datastore solution . Mostly thanks to its high Speeds , Low latency and high Read/Write throughputs .
Even after decades of release , redis has shown to be capable of handling emerging workload . Which screams of some of the great design decisions made by the redis team .
In this blog we are going into redis internals and decoding the magic behind redis’s high performance. Let’s get straight into it :
Redis is based on memory (RAM).
It is completely based on memory ( stores data on the RAM) . As memory access is orders of magnitude faster than Random Disk I/O . Pure memory access provides high Read/Write throughput and a low latency .
For instance random memory access is about 100,000 faster than the disk counterpart .
While storing Data in memory is one of most important factor for the performance of redis. It also leads to the drawback that the dataset stored can not be larger than the memory .

It is single threaded
Redis operates as a single process and primarily uses a single thread for operations .
As single a threaded process it has not to worry about syncronisation mechanisms like Locks .
The use of single thread avoids unnecessary context switching and race conditions,
and there is no multi-process or multi-thread switching that consumes CPU.
Being single-threaded, Redis favors fast CPUs with large caches and not many cores
Well that’s great but if its single threaded how does it do 1 million requests per sec?
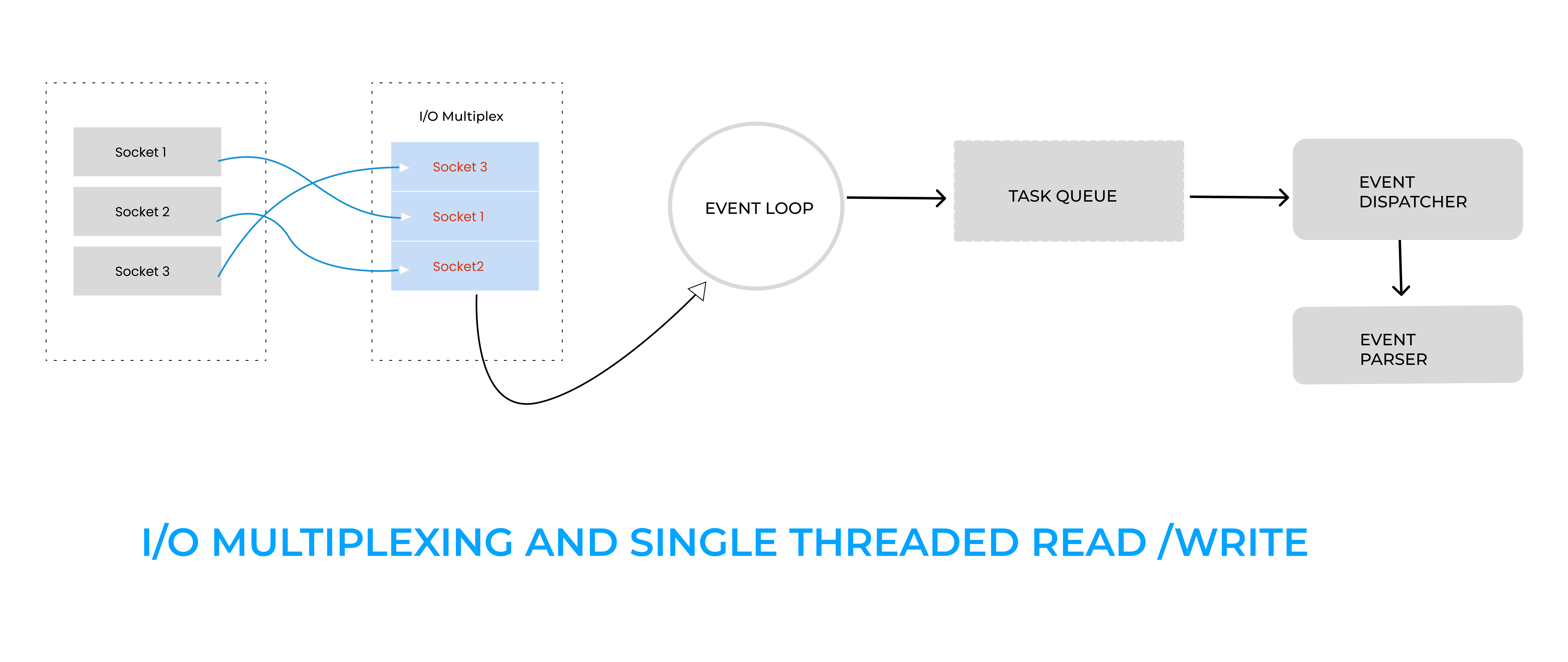
Rather than using blocking I/O or traditional non blocking I/O . Redis uses Multiple Multiplexing I/O for socket connections.
Using multiple I / O multiplexing technology allows a single thread to efficiently process multiple connection requests (reduce the time consumption of network IO as much as possible), and Redis operates data in memory very fast, which means that operations in memory are not a bottleneck that affects Redis performance .
The multiplex I / O multiplexing model utilizes the ability of select, poll, and epoll to simultaneously monitor I / O events of multiple streams In simple words , I/O Multiplexing is the capability to tell the kernel that we want to be notified if one or more I/O connections are ready , like input is ready to be read . Can be used when client handles multiple sockets at the same time.
Uses several low level efficient datastructures .
Being an in-memory datastore redis can leverage several effiecient low level datastructures like LinkedLists , Hashtables , HashSet , HyperlogLogs with worrrying about persistence .
In memory datatypes are easy to reason about and hence can be optimized for space and performance .
Data types are optimized to use less space up to a certain size. Hashes, Lists, Sets composed of just integers, and Sorted Sets, when smaller than a given number of elements, and up to a maximum element size, are encoded in a very memory efficient way that uses up to 10 times less memory (with 5 time less memory used being the average saving).
more about redis memory optimization here
References :